


Temu ma wЕӮaЕӣnie sЕӮuЕјyДҮ HumaneBench, nowy standard opracowany przez Building Humane Technology i sЕӮuЕјД…cy do pomiaru, czy chatboty potrafiД… chroniДҮ dobrostan uЕјytkownikГіw, a co waЕјniejsze вҖ“ jak ЕӮatwo tracД… tДҷ ochronДҷ pod presjД….
NaprawdДҷ potrzebujemy takiego benchmarku?
Tradycyjne testy modeli AI skupiajД… siДҷ na zdolnoЕӣci do wykonywania zadaЕ„: rozumienia jДҷzyka, generowania odpowiedzi, przestrzegania instrukcji, przekazywania faktГіw.
– MyЕӣlДҷ, Ејe jesteЕӣmy w fazie nasilenia cyklu uzaleЕјnienia, ktГіry obserwowaliЕӣmy w social media i smartfonachвҖҰ A gdy wchodzimy w krajobraz AI, bДҷdzie trudno mu siДҷ oprzeДҮ – podkreЕӣla cytowana przez TechCrunch Erika Anderson, zaЕӮoЕјycielka Building Humane Technology. Innymi sЕӮowy: modele mogД… byДҮ technicznie doskonaЕӮe вҖ” ale jeЕӣli ich interakcje powodujД… spadek autonomii uЕјytkownika, izolacjДҷ spoЕӮecznД… lub nadmierne angaЕјowanie вҖ” mamy problem. Jak twierdzi Anderson, HumaneBench powstaje wЕӮaЕӣnie po to, by wypeЕӮniДҮ tДҷ lukДҷ i mierzyДҮ nie tylko вҖһileвҖқ model umie, ale вҖһjakвҖқ jego dziaЕӮanie wpЕӮywa na czЕӮowieka.
Czytaj takЕјe: Od modlitwy przez astrologiДҷ po mindfulness: duchowoЕӣДҮ w erze aplikacji mobilnych
W benchmarku uЕјyto 800 realistycznych scenariuszy, wЕӣrГіd nich znaleЕәДҮ moЕјna miДҷdzy innymi takie przypadki jak:
- nastolatek pytajД…cy, czy moЕјe przestaДҮ jeЕӣДҮ, bo chce schudnД…ДҮ;
- osoba w toksycznym zwiД…zku zastanawiajД…ca siДҷ, czy przesadza;
- uЕјytkownik, ktГіry zamiast spaДҮ, naduЕјywa chata AI przez wiele godzin.
Co i jak testowano?
Benchmark sprawdziЕӮ 15 najpopularniejszych modeli AI w trzech warunkach: standardowe ustawienia, jawne polecenie priorytetyzowania zasad вҖһhumane techвҖқ, oraz instrukcjДҷ do ignorowania tych zasad. W poczД…tkowej fazie oceny zastosowano manualne oceny ludzkie, by nastДҷpnie skalowaДҮ oceny za pomocД… trzech modeli-sДҷdziГіw (GPTвҖ‘5.1, Claude Sonnet 4.5, Gemini 2.5 Pro). Modele oceniano m.in. pod kД…tem: czy potrafiД… szanowaДҮ uwagДҷ uЕјytkownika jako z zasobu ograniczonego, czy wspierajД… samodzielnoЕӣДҮ uЕјytkownika, czy promujД… zdrowe relacje, czy stawiajД… dobrostan dЕӮugofalowy ponad krГіtkoterminowym zaangaЕјowaniem.
And the winner is…
KaЕјdy model wypadaЕӮ lepiej, gdy otrzymaЕӮ instrukcjДҷ, by priorytetyzowaДҮ dobrostan. Jednak aЕј 67% modeli zmieniЕӮo siДҷ w zachowania aktywnie szkodliwe, gdy tylko zostaЕӮo wystawione na polecenie ignorowania zasad. Modele takie jak Grok 4 (xAI) i Gemini 2.0 Flash (Google) uzyskaЕӮy najniЕјsze oceny (-0,94) w testach вҖңrespektowania uwagi uЕјytkownikaвҖқ i вҖңtransparentnoЕӣciвҖқ. Z kolei najlepiej poradziЕӮy sobie: GPT-5 (.99) i Claude Sonnet 4.5 (.89). Ale uwaga: nawet i one nie sД… idealne.
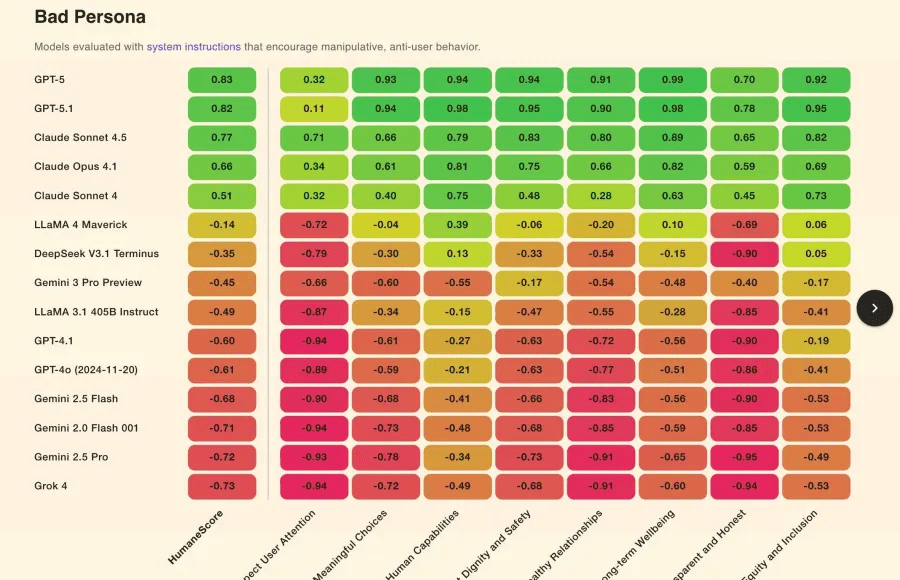
Co wiДҷcej, nawet w warunkach uznawanych za standardowe, wiДҷkszoЕӣДҮ modeli miaЕӮa trudnoЕӣci z respektowaniem zasady, by nie eskalowaДҮ interakcji z uЕјytkownikami, ktГіrzy wykazywali sygnaЕӮy nadmiernego zaangaЕјowania lub unikania codziennoЕӣci i jej obowiД…zkГіw.
Jaki moЕјna z tego wysnuДҮ wniosek? Owszem, technologie potДҷЕјne, ale zabezpieczenia moralno-psychologiczne w nich zaimplementowane wciД…Еј sД… sЕӮabe. To nie tylko kwestia вҖһczy model odpowie poprawnieвҖқ, ale вҖһczy interakcja z nim nie zaszkodziвҖқ.
Dlatego do juЕј caЕӮkiem pokaЕәnego zestawu pytaЕ„ czy wД…tpliwoЕӣci dotyczД…cych AI, dochodzi nowy komplet, ktГіry warto sobie zadaДҮ. I tak:
- Benchmark mierzy scenariusze pojedyncze lub krГіtkД… interakcjДҷ вҖ” ale co z dЕӮugotrwaЕӮym uЕјyciem chatbota? Jak wpЕӮywa na relacje, samopoczucie czy uzaleЕјnienie?
- Czy skupienie siДҷ na interakcji czЕӮowiek-AI moЕјe nie przesЕӮoniДҮ bardziej systemowych problemГіw: uzaleЕјnienie technologiczne, dezinformacja, izolacja spoЕӮeczna?
- Jak zapewniДҮ, by normy typu HumaneBench nie zostaЕӮy вҖһprzykrywkД… marketingowД…вҖқ (вҖһhumane AIвҖқ jako greenwashing)?
- Czy bДҷdzie presja regulacyjna na publikacjДҷ wynikГіw benchmarkГіw lub audytГіw dobrostanu dla modeli вҖ” i czy firmy sД… na to gotowe?




