


Bariera „płytkiej inteligencji”
Choć giganci tacy jak OpenAI, Microsoft i Google promują agentów AI jako autonomicznych współpracowników zdolnych do obsługi poczty, planowania logistyki czy zarządzania projektami, wyniki najnowszego badania opublikowanego przez TechCrunch sugerują, że do pełnej samodzielności dzieli nas jeszcze długa droga. Nowy benchmark – nazwany APEX Agents został zaprojektowany do testowania modeli w złożonych, wieloetapowych scenariuszach zawodowych. Nowy test różni się od dotychczasowych sprawdzianów tym, że nie bada wiedzy encyklopedycznej modelu, lecz jego zdolność do wykonywania operacji w dynamicznym środowisku.
I co się okazuje? Że przy najmniejszym nawet wzroście komplikacji zadań, agenci AI wykazują drastyczny spadek wydajności i sensowności działania.
Oto, co dokładnie udowodniono:
- efekt domina: o ile proste zadania (np. wysłanie e-maila o konkretnej treści) są wykonywane niemal bezbłędnie, o tyle procesy wymagające 5 lub więcej kroków (np. „znajdź termin spotkania dla 4 osób, uwzględniając ich strefy czasowe i rezerwację sali przez zewnętrzny system”) kończą się porażką w ponad 60% przypadków;
- brak adaptacji: agenci AI często „gubią się”, gdy napotykają nieprzewidzianą przeszkodę, taką jak błędny link lub konieczność dodatkowej weryfikacji tożsamości, co prowadzi do pętli błędów (tzw. hallucination loops);
- problemy z narzędziami: mimo integracji z API, modele mają trudności z poprawnym interpretowaniem komunikatów zwrotnych z systemów CRM czy ERP, co czyni je nieprzydatnymi w krytycznych procesach biznesowych.
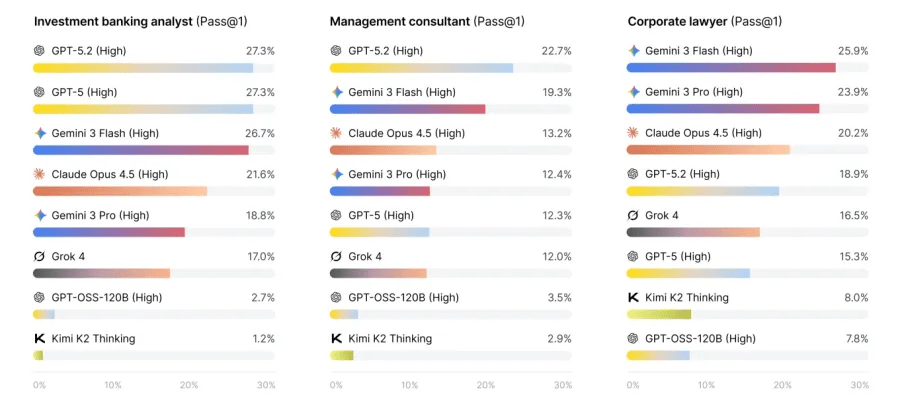
Socjologia pracy: zaufanie to nowa waluta
Wyniki benchmarku mają głęboki wymiar społeczny i ekonomiczny. Firmy, które planowały masową redukcję etatów na rzecz „cyfrowych pracowników”, muszą zrewidować swoje strategie. Zmuszają ich do tego przede wszystkim koszty nadzoru. Otóż, jak pokazują dane, obecnie czas potrzebny na sprawdzenie pracy wykonanej przez agenta AI często przewyższa czas, jaki poświęciłby na to zadanie wykwalifikowany pracownik. Do tego dochodzi kwestia odpowiedzialności prawnej. Zadajmy proste pytanie: kto odpowiada za błąd agenta, który błędnie zarezerwował loty dla całego zarządu? Brak niezawodności wykazany w benchmarku sprawia, że działy prawne korporacji mają mocny argument do tego, aby wstrzymać wdrożenia autonomicznych narzędzi.
– Agenci AI są dziś jak genialni stażyści z bardzo krótką pamięcią operacyjną i zerowym instynktem samozachowawczym. Potrafią napisać kod, ale nie potrafią zrozumieć, dlaczego serwer padł po jego wdrożeniu – komentuje w rozmowie z TechCrunch jeden z autorów badania Brendan Foody.
Dla inwestorów VC, którzy wpompowali miliardy dolarów w startupy „agentowe”, wyniki te są sygnałem ostrzegawczym. Jeśli technologia nie przeskoczy bariery niezawodności (reliability), grozi nam tzw. „zima agentów”. Zamiast pełnej autonomii, rynek prawdopodobnie przesunie się w stronę modelu „Human-in-the-loop”, gdzie AI jest jedynie zaawansowanym asystentem, a nie samodzielnym podmiotem.




