


„Wyszukiwanie orzeczeń i przepisów” to nie jest nowy pomysł. Co dokładnie w Waszym narzędziu sprawia, że mamy do czynienia z „innowacją” a nie po prostu z kolejną wyszukiwarką z lepszym UX?
To prawda, samo „wyszukiwanie orzeczeń i przepisów” nie jest nowym pomysłem. Ale Zapytaj Kodeks nie konkuruje z innymi narzędziami tym, co robi – tylko tym, jak to robi. Nasza innowacja polega na tym, że użytkownik nie musi znać ani sygnatur, ani słów kluczowych, ani struktury aktów prawnych. Wystarczy, że zada pytanie w języku naturalnym. System rozumie kontekst i znajduje nie tylko orzeczenia, ale też powiązane przepisy, streszczenia i tezy. To realna różnica w codziennej pracy z prawem.
W testach pilotażowych średni czas dotarcia do właściwego orzeczenia wyniósł zaledwie 60 sekund. Dla porównania, w tradycyjnych bazach wyszukiwanie tego samego orzeczenia potrafi zająć kilka godzin, co pokazuje, jak znacząco nasze narzędzie usprawnia pracę z orzecznictwem.
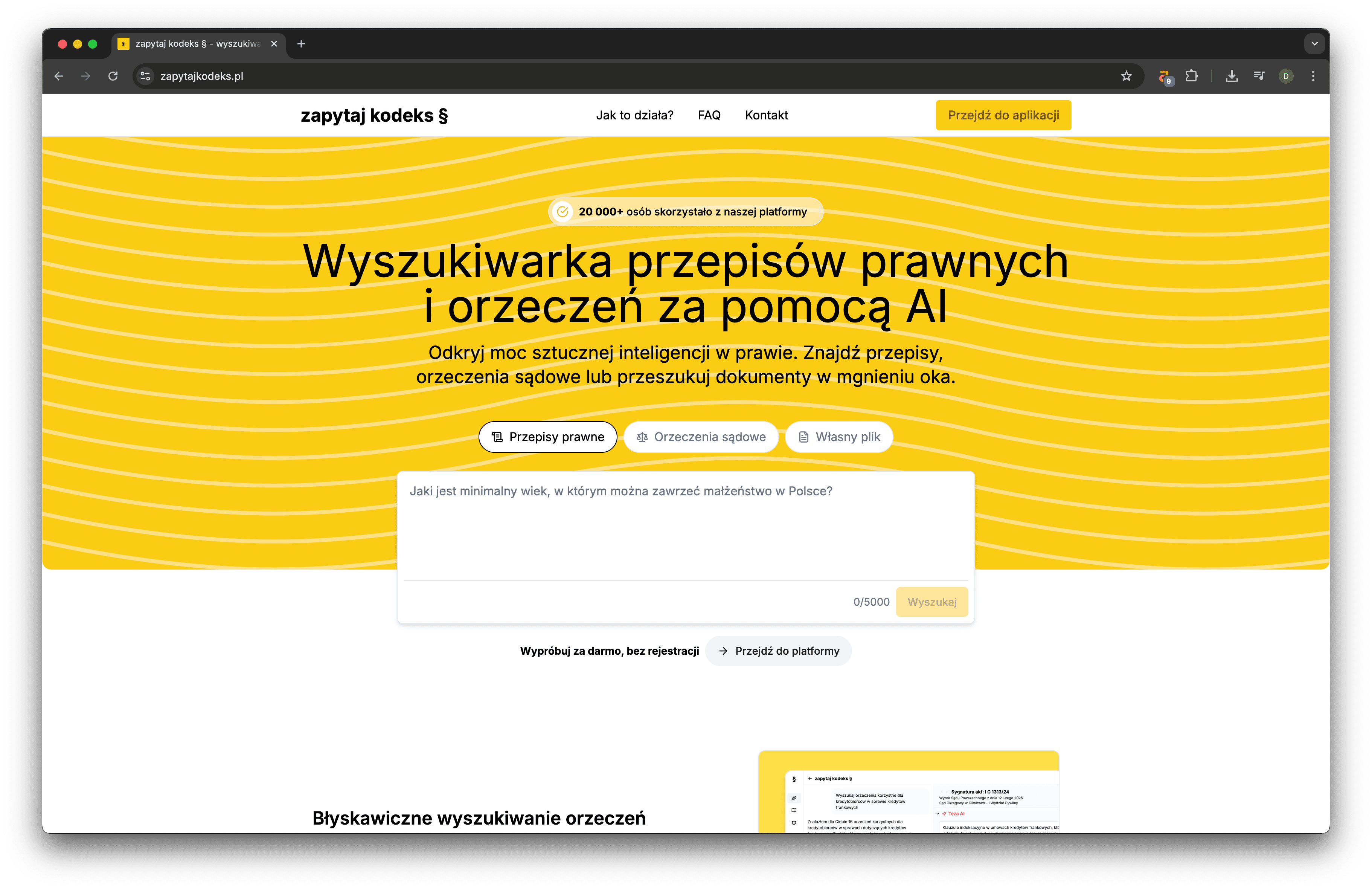
W praktyce kancelarii oznacza to realną oszczędność czasu i większą precyzję przy analizie orzecznictwa, szczególnie w sprawach nietypowych, w których standardowe bazy nie zwracają trafnych wyników. Narzędzie może być wykorzystywane zarówno do szybkiego sprawdzenia aktualnej linii orzeczniczej, jak i do przygotowania się do opinii prawnej czy uzasadnienia stanowiska w piśmie procesowym. Co istotne, korzystają z niego nie tylko indywidualni prawnicy, ale również całe zespoły np. do wstępnej selekcji orzeczeń w większych sprawach.
W jakim stopniu Wasz system rozumie kontekst prawny zapytania? Czy potrafi odróżnić zapytanie laika od pytania prawnika? Jak radzi sobie z językiem potocznym, niedookreślonym lub wieloznacznym?
System został zaprojektowany tak, by rozumieć intencję użytkownika, niezależnie od tego, czy zapytanie pochodzi od prawnika, czy od osoby bez wykształcenia prawniczego. Dzięki wykorzystaniu modeli językowych, system potrafi interpretować język potoczny, niedookreślony czy wieloznaczny. Co ważne – jeśli pytanie jest nieprecyzyjne lub może mieć wiele możliwych interpretacji, system nie zgaduje w ciemno. Zamiast tego potrafi zadać użytkownikowi doprecyzowujące pytanie.
Przykładowo, jeśli użytkownik wpisze „kara za pogryzienie przez psa” – system wskaże podstawy prawne odpowiedzialności właściciela zwierzęcia, które mogą mieć zastosowanie w takiej sytuacji. Dzięki temu, nawet osoby niebędące prawnikami mogą skutecznie rozpocząć poszukiwanie rozwiązania, a profesjonaliści zyskać przyspieszoną i precyzyjniejszą analizę konkretnego wątku.
Na jakich danych był trenowany Wasz model AI? Czy korzystacie z własnej bazy, danych publicznych, a może z zewnętrznych dostawców? Jak rozwiązujecie kwestie licencyjne i zgodności z prawem autorskim w przypadku analizy orzeczeń i przepisów?
Nie wykorzystujemy danych od zewnętrznych dostawców komercyjnych ani zamkniętych zbiorów. Wyszukiwanie odbywa się na podstawie publicznych, rządowych źródeł, co pozwala zachować pełną zgodność z obowiązującymi przepisami dotyczącymi praw autorskich i ponownego wykorzystywania informacji sektora publicznego.
W Polsce mamy na szczęście dobrze rozwinięty system publikacji aktów prawnych i orzeczeń – nasz system prawny jest mocno zdigitalizowany, a dane są oficjalnie udostępniane na stronach administracji publicznej. Problemem jest jednak ich rozproszenie oraz zróżnicowany format – przepisy są publikowane w jednym miejscu, każda instancja sądu ma swój portal z udostępnionymi orzeczeniami, a ich struktura i forma nie są jednolite.
Obecnie indeksujemy ponad 500 tysięcy orzeczeń sądowych z Sądów powszechnych, Sądu Najwyższego czy Trybunału Konstytucyjnego. Jesteśmy również na etapie wdrażania orzeczeń z Sądu Administracyjnego.
AI bywa przekonująca – ale również omylna. Jakie mechanizmy macie wbudowane, aby zminimalizować ryzyko tzw. „halucynacji”, czyli generowania fałszywych lub wprowadzających w błąd informacji prawnych?
Mamy świadomość, że narzędzia ogólne, jak ChatGPT czy inne LLM-y, nieprzystosowane do pracy z prawem, potrafią generować fałszywe sygnatury, wymyślać nieistniejące przepisy czy przekręcać treść orzeczeń.
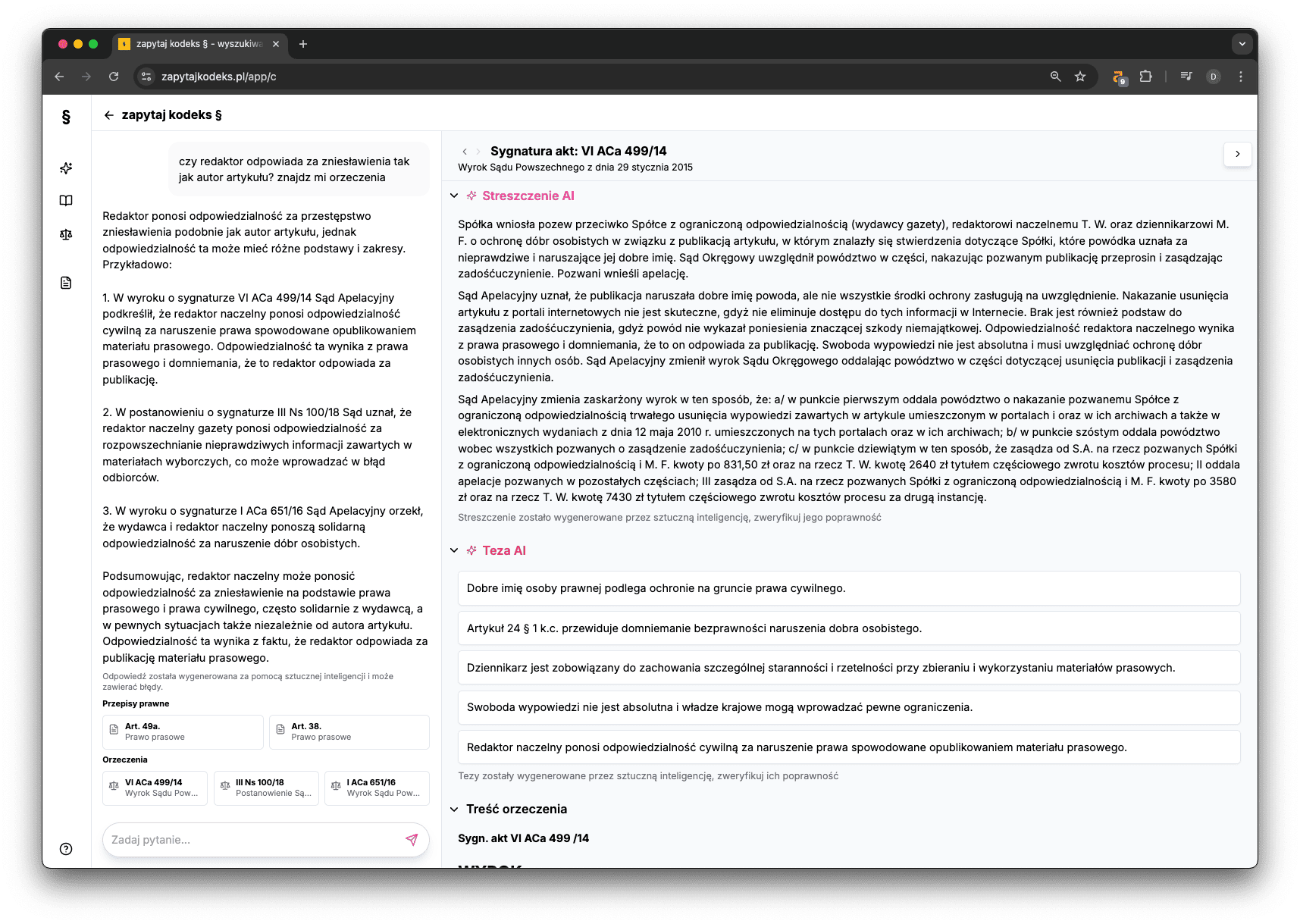
Nasz system nie generuje odpowiedzi „z głowy”. Skupia się przede wszystkim na wyszukiwaniu rzetelnych źródeł – przepisów i orzeczeń – z wykorzystaniem sztucznej inteligencji i zaawansowanych algorytmów semantycznych. To właśnie te źródła są podstawą każdej odpowiedzi. Dla każdej odpowiedzi użytkownik otrzymuje wskazane konkretne akty prawne, artykuły, orzeczenia lub ich fragmenty – z możliwością kliknięcia i przeczytania oryginalnego tekstu w całości. System niczego nie „wymyśla” bo działa jak inteligentna wyszukiwarka, która porządkuje informacje i prezentuje je w sposób zrozumiały.
Czy w przypadku błędnej interpretacji przepisów lub orzeczeń przez Waszą platformę użytkownik ma prawo do reklamacji, a może ponosicie jakąś odpowiedzialność? Co jeśli skutkiem będzie błędna decyzja np. przedsiębiorcy?
Platforma Zapytaj Kodeks nie zastępuje konsultacji z prawnikiem ani nie pełni roli doradcy prawnego. Celem systemu nie jest interpretacja przepisów, a znalezienie go. To narzędzie wspomagające – stworzone po to, by szybciej dotrzeć do odpowiednich przepisów i orzeczeń, a nie po to, by wydawać wiążące opinie prawne. Użytkownik korzysta z systemu jako narzędzia informacyjnego, a nie jako zastępstwa porady prawnej. My zapewniamy dostęp do uporządkowanych źródeł, ale ostateczna ocena zawsze należy do człowieka.
Wszystkie dodatkowe informacje generowane przez sztuczną inteligencję – takie jak streszczenia orzeczeń, uproszczone wyjaśnienia, propozycje tez czy odpowiedzi w języku naturalnym są wyraźnie oznaczone jako generowane przez AI. Zachęcamy użytkowników do samodzielnej weryfikacji oryginalnych źródeł, które są zawsze dostępne obok treści generowanej przez system.
Czy nie obawiacie się, że aplikacja w rękach laika – pozbawionego prawniczego wykształcenia – może prowadzić do niebezpiecznego „samoleczenia prawnego”? Jak przeciwdziałacie takim ryzykom?
To słuszne i bardzo ważne pytanie. Od początku zakładamy, że nasze narzędzie ma pełnić rolę pomocniczą, a nie zastępować profesjonalną pomoc prawną. Wierzymy, że umożliwienie osobie niebędącej prawnikiem wstępnego zrozumienia problemu prawnego może pomóc jej lepiej przygotować się do konsultacji z profesjonalistą a nie ją zastąpić.
Ułatwiamy start, porządkujemy informacje i wskazujemy źródła, ale sam system został stworzony po to, by zachęcać do sięgania po pomoc doświadczonych prawników, a nie ją zastępować – zwłaszcza w sprawach złożonych lub mających istotne konsekwencje.
W jaki sposób testowaliście trafność wyników? Czy przeprowadziliście audyty efektywności np. w porównaniu do tradycyjnych narzędzi prawniczych jak Lex czy Legalis? Macie twarde dane?
Na obecnym etapie Zapytaj Kodeks jest w fazie zaawansowanych testów z udziałem praktyków prawa – kancelarii, aplikantów i studentów prawa, którzy mają nielimitowany dostęp do systemu i dzielą się z nami realnym feedbackiem z pracy nad konkretnymi sprawami. W ten sposób badamy zarówno trafność wyszukiwania, jak i użyteczność funkcji takich jak streszczanie orzeczeń czy powiązania z przepisami.
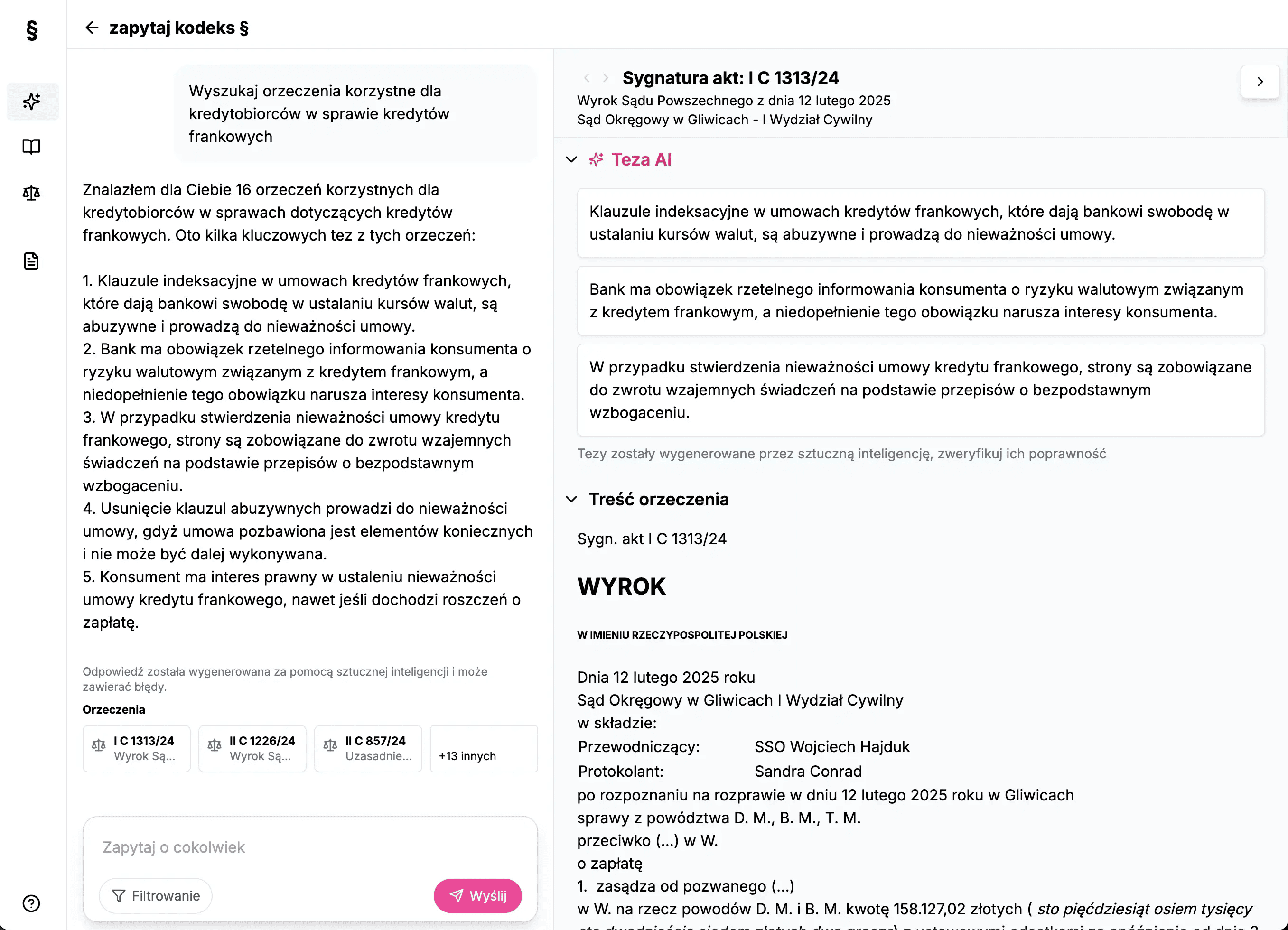
Choć nie przeprowadziliśmy jeszcze formalnego audytu porównawczego z narzędziami typu Lex czy Legalis, zbieramy już dane jakościowe i ilościowe na temat czasu wyszukiwania, trafności wyników oraz poziomu satysfakcji użytkowników. Platformę odwiedziło ponad 20 000 użytkowników i na ten moment opinie są przytłaczająco pozytywne.
Wierzymy w przejrzystość – dlatego nie twierdzimy, że system już dziś zastępuje tradycyjne narzędzia. Ale w wielu przypadkach znacząco skraca czas dotarcia do kluczowych informacji i pomaga uporządkować źródła – szczególnie w pracy indywidualnych prawników, mniejszych kancelarii czy studentów.
Czy Wasz system opiera się na gotowym LLM (np. GPT-4), czy rozwijacie własny model? A jeśli korzystacie z zewnętrznych rozwiązań, to czy użytkownicy mają świadomość, że ich dane mogą trafiać do podmiotów trzecich?
System wykorzystuje kombinację zaawansowanych dużych modeli językowych (LLM) dostarczanych przez wiodących dostawców, takich jak OpenAI czy Google, dobieranych dynamicznie w zależności od funkcji, rodzaju zapytania oraz wymagań kontekstowych. W zależności od przypadku, system może wykorzystywać różne modele do streszczania orzeczeń, interpretacji zapytań w języku naturalnym czy wspomagania klasyfikacji treści prawnych.
Korzystamy wyłącznie z API w wersjach komercyjnych, w których producenci gwarantują, że dane nie są wykorzystywane do trenowania modeli. Dodatkowo, użytkownicy są informowani o sposobie przetwarzania zapytań w naszej polityce prywatności.
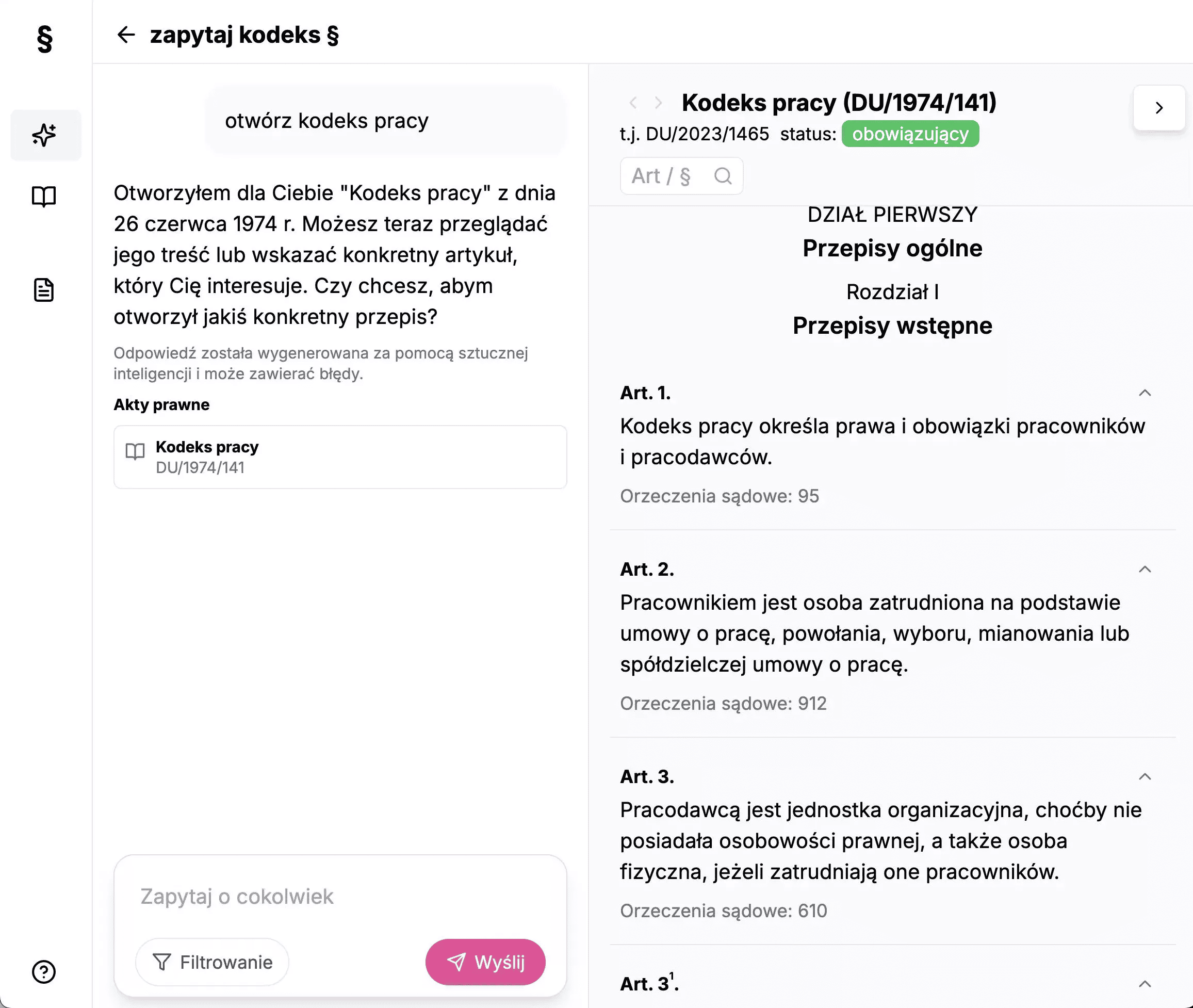
Jak podchodzicie do problemu „opóźnienia legislacyjnego”? AI często bazuje na danych historycznych – jak zapewniacie, że odpowiedzi są aktualne w kontekście zmieniających się przepisów, nowelizacji, uchwał SN itd.?
To bardzo ważna kwestia i również jedna z głównych różnic między Zapytaj Kodeks a ogólnymi narzędziami AI. W naszym przypadku modele językowe, pełnią jedynie pomocniczą funkcję językową. Kluczowe dane, czyli przepisy prawne i orzeczenia pochodzą z naszej własnej bazy, która jest automatycznie i regularnie aktualizowana z oficjalnych rządowych źródeł.
Wasze narzędzie brzmi jak coś, co może zmniejszyć zapotrzebowanie na prawników. Jak reaguje na to środowisko prawnicze? Mieliście już jakieś starcia z izbami adwokackimi czy radcowskimi?
Wręcz przeciwnie, naszym zdaniem Zapytaj Kodeks nie zmniejszy zapotrzebowania na prawników, a je zwiększy.
Z jednej strony aplikacja pozwala osobom nieposiadającym wykształcenia prawniczego lepiej zrozumieć swój problem, dzięki czemu są bardziej świadome i chętniej szukają profesjonalnej pomocy. Z drugiej, prawnicy sami zyskują bardzo konkretne narzędzie, które znacząco skraca czas potrzebny na research orzeczniczy i wyszukiwanie przepisów, bez konieczności żmudnego przeszukiwania kilku baz równocześnie. Wierzymy, że w efekcie każdy zyskuje: użytkownik szybciej otrzymuje lepiej dopasowaną pomoc, a prawnik może skupić się na analizie, interpretacji i strategii, zamiast na szukaniu podstawy prawnej przez kilkadziesiąt minut. To wsparcie, nie konkurencja.
Co więcej, wielu prawników, z którymi współpracujemy podczas testów, podkreśla, że takie narzędzie może szczególnie pomóc mniejszym kancelariom, aplikantom czy studentom prawa. Do tej pory nie mieliśmy żadnych sporów z izbami a przeciwnie, jesteśmy otwarci na rozmowę i współpracę, bo naszym celem nie jest wypieranie zawodu, lecz wspieranie go nowoczesną technologią.
Jeśli są Państwo zainteresowani wdrożeniem w kancelarii, testami zespołowymi lub rozmową o funkcjach dla profesjonalistów – zapraszamy do kontaktu przez formularz na naszej stronie zapytajkodeks.pl. Chętnie pokażemy, jak narzędzie działa w konkretnych scenariuszach zawodowych. Natomiast jeżeli ktoś z czytelników chciałby sam sprawdzić, jak to wygląda w praktyce można przetestować narzędzie za darmo, bez rejestracji.




